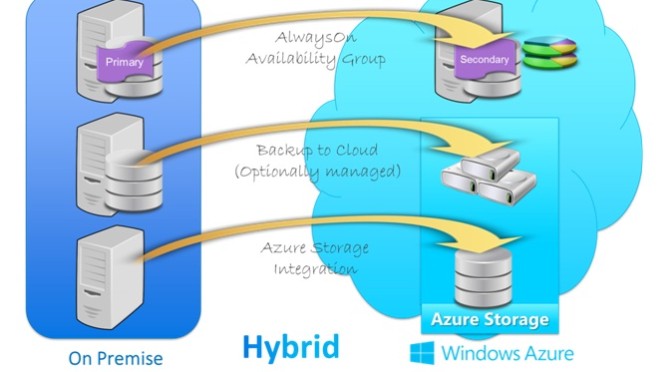
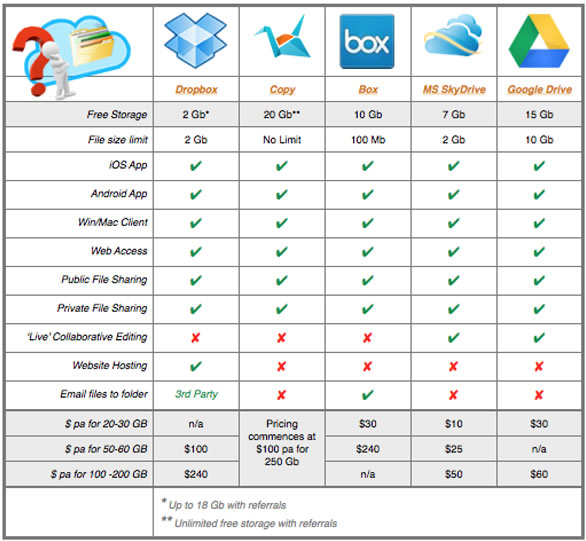
The waterfall model is the most predictive of the methodologies, stepping through requirements capture, analysis, design, coding, and testing in a strict, pre-planned sequence. Progress is generally measured in terms of deliverable artifacts – requirement specifications, design documents, test plans, code reviews and the like. The waterfall model can result in a substantial integration and testing effort toward the end of the cycle, a time period typically extending from several months to several years. The size and difficulty of this integration and testing effort is one cause of waterfall project failure.
Though there have been several variations of this methodologies preached for development of software in a planned and predictive manner, like spiral or iterative development, but I have seen most software development is a chaotic activity, often characterized by the phrase “code and fix”. The software is written without much of an underlying plan, and the design of the system is cobbled together from many short term decisions. This actually works pretty well as the system is small, but as the system grows it becomes increasingly difficult to add new features to the system. Furthermore bugs become increasingly prevalent and increasingly difficult to fix. A typical sign of such a system is a long test phase after the system is “feature complete”. Such a long test phase plays havoc with schedules as testing and debugging is impossible to schedule.
Reason 1: We need to separate design from construction, and this does suits us
Because the approach for software engineering methodologies looks like this: we want a predictable schedule that can use people with lower skills. To do this we must separate design from construction. Therefore we need to figure out how to do the design for software so that the construction can be straightforward once the planning is done. So what form does this plan take? For many, this is the role of design notations such as the UML. If we can make all the significant decisions using the UML, we can build a construction plan and then hand these designs off to coders as a construction activity. But here lies the crucial question. Can you get a design that is capable of turning the coding into a predictable construction activity? And if so, is cost of doing this sufficiently small to make this approach worthwhile?
All of this brings a few questions to mind. The first is the matter of how difficult it is to get a UML-like design into a state that it can be handed over to programmers. The problem with a UML-like design is that it can look very good on paper, yet be seriously flawed when you actually have to program the thing. The only checking we can do of UML-like diagrams is peer review. While this is helpful it leads to errors in the design that are often only uncovered during coding and testing. Even skilled designers, such as I consider myself to be, are often surprised when we turn such a design into software. Another issue is that of comparative cost. When you build a bridge, the cost of the design effort is about 10% of the job, with the rest being construction. In software the amount of time spent in coding is much, much less experts suggests that for a large project, only 15% of the project is code and unit test, an almost perfect reversal of the bridge building ratios. Even if you lump in all testing as part of construction, then design is still 50% of the work. This raises an important question about the nature of design in software compared to its role in other branches of engineering.
These kinds of questions led many like me to suggest that in fact the source code is a design document and that the construction phase is actually the use of the compiler and linker. Indeed anything that you can treat as construction can and should be automated.
This thinking leads to some important conclusions:
— In software: construction is so cheap as to be free
— In software all the effort is design, and thus requires creative and talented people
— Creative processes are not easily planned, and so predictability may well be an impossible target
— We should be very wary of the traditional engineering metaphor for building software. It’s a different kind of activity and requires a different process
Reason 2: The Unpredictability of Requirements
There’s a refrain I’ve heard on every problem project I’ve run into. The developers come to me and say “the problem with this project is that the requirements are always changing”. The thing I find surprising about this situation is that anyone is surprised by it. In building business software requirements changes are the norm, the question is what we do about it. One route is to treat changing requirements as the result of poor requirements engineering. The idea behind requirements engineering is to get a fully understood picture of the requirements before you begin building the software, get a customer sign-off to these requirements, and then set up procedures that limit requirements changes after the sign-off.
One problem with this is that just trying to understand the options for requirements is tough. It’s even tougher because the development organization usually doesn’t provide cost information on the requirements. You end up being in the situation where you may have some desire for a sun roof on your car, but the salesman can’t tell you if it adds $10 to the cost of the car, or $10,000. Without much idea of the cost, how can you figure out whether you want to pay for that sunroof? Estimation is hard for many reasons. Part of it is that software development is a design activity, and thus hard to plan and cost. Part of it is that the basic materials keep changing rapidly. Part of it is that so much depends on which individual people are involved, and individuals are hard to predict and quantify. Software’s intangible nature also cuts in. It’s very difficult to see what value a software feature has until you use it for real. Only when you use an early version of some software do you really begin to understand what features are valuable and what parts are not.
This leads to the ironic point that people expect that requirements should be changeable. After all software is supposed to be soft. So not just are requirements changeable, they ought to be changeable. It takes a lot of energy to get customers of software to fix requirements. It’s even worse if they’ve ever dabbled in software development themselves, because then they “know” that software is easy to change. But even if you could settle all that and really could get an accurate and stable set of requirements you’re probably still doomed. In today’s economy the fundamental business forces are changing the value of software features too rapidly. What might be a good set of requirements now, is not a good set in six months time. Even if the customers can fix their requirements, the business world isn’t going to stop for them. And many changes in the business world are completely unpredictable: anyone who says otherwise is either lying, or has already made a billion on stock market trading.
Everything else in software development depends on the requirements. If you cannot get stable requirements you cannot get a predictable plan.
Reason 3: Is Predictability Impossible?
In general, No. There are some software developments where predictability is possible. Organizations such as NASA’s space shuttle software group are a prime example of where software development can be predictable. It requires a lot of ceremony, plenty of time, a large team, and stable requirements. There are projects out there that are space shuttles. However I don’t think much business software fits into that category. For this you need a different kind of process. One of the big dangers is to pretend that you can follow a predictable process when you can’t. People who work on methodology are not very good at identifying boundary conditions: the places where the methodology passes from appropriate in inappropriate. Most methodologists want their methodologies to be usable by everyone, so they don’t understand nor publicize their boundary conditions. This leads to people using a methodology in the wrong circumstances, such as using a predictable methodology in an unpredictable situation.
There’s a strong temptation to do that. Predictability is a very desirable property. However if you believe you can be predictable when you can’t, it leads to situations where people build a plan early on, then don’t properly handle the situation where the plan falls apart. You see the plan and reality slowly drifting apart. For a long time you can pretend that the plan is still valid. But at some point the drift becomes too much and the plan falls apart. Usually the fall is painful. So if you are in a situation that isn’t predictable you can’t use a predictive methodology. That’s a hard blow. It means that many of the models for controlling projects, many of the models for the whole customer relationship, just aren’t true any more. The benefits of predictability are so great, it’s difficult to let them go. Like so many problems the hardest part is simply realizing that the problem exists.
Reason 4: The Adaptive Customer
This kind of adaptive process requires a different kind of relationship with a customer than the ones that are often considered, particularly when development is done by a separate firm. When you hire a separate firm to do software development, most customers would prefer a fixed-price contract. Tell the developers what they want, ask for bids, accept a bid, and then the onus is on the development organization to build the software. A fixed price contract requires stable requirements and hence a predictive process. Adaptive processes and unstable requirements imply you cannot work with the usual notion of fixed-price. Trying to fit a fixed price model to an adaptive process ends up in a very painful explosion. The nasty part of this explosion is that the customer gets hurt every bit as much as the software development company. After all the customer wouldn’t be wanting some software unless their business needed it. If they don’t get it their business suffers. So even if they pay the development company nothing, they still lose. Indeed they lose more than they would pay for the software (why would they pay for the software if the business value of that software were less?). So there’s dangers for both sides in signing the traditional fixed price contract in conditions where a predictive process cannot be used. This means that the customer has to work differently. This doesn’t mean that you can’t fix a budget for software up-front. What it does mean is that you cannot fix time, price and scope.